

What is a Fuzzer?
Inspiration: I wrote my undergrad Thesis on a new distributed fuzzer called Hopper that I built, and I always get the question: "What is a Fuzzer", so here it is.
Introduction
A fuzzer is a security tool that industry and researchers have been using to find vulnerabilities and exploits in systems for the past three decades. It all started when a paper titled An Empirical Study of the Reliability of UNIX Utilities was published in 1990, leading to a revolution in the way we think about Security. At its core, Fuzzing is a process where we take pseudo-randomly generated inputs that can be valid, invalid, or unexpected and feed them to the program under test (PUT). The program is then monitored for crashes or unexpected behavior that could evince bugs or vulnerabilities in the software. Inputs to the program are called "seeds", and are typically generated from a group of semantically correct initial inputs, usually called the “corpus” of seeds.
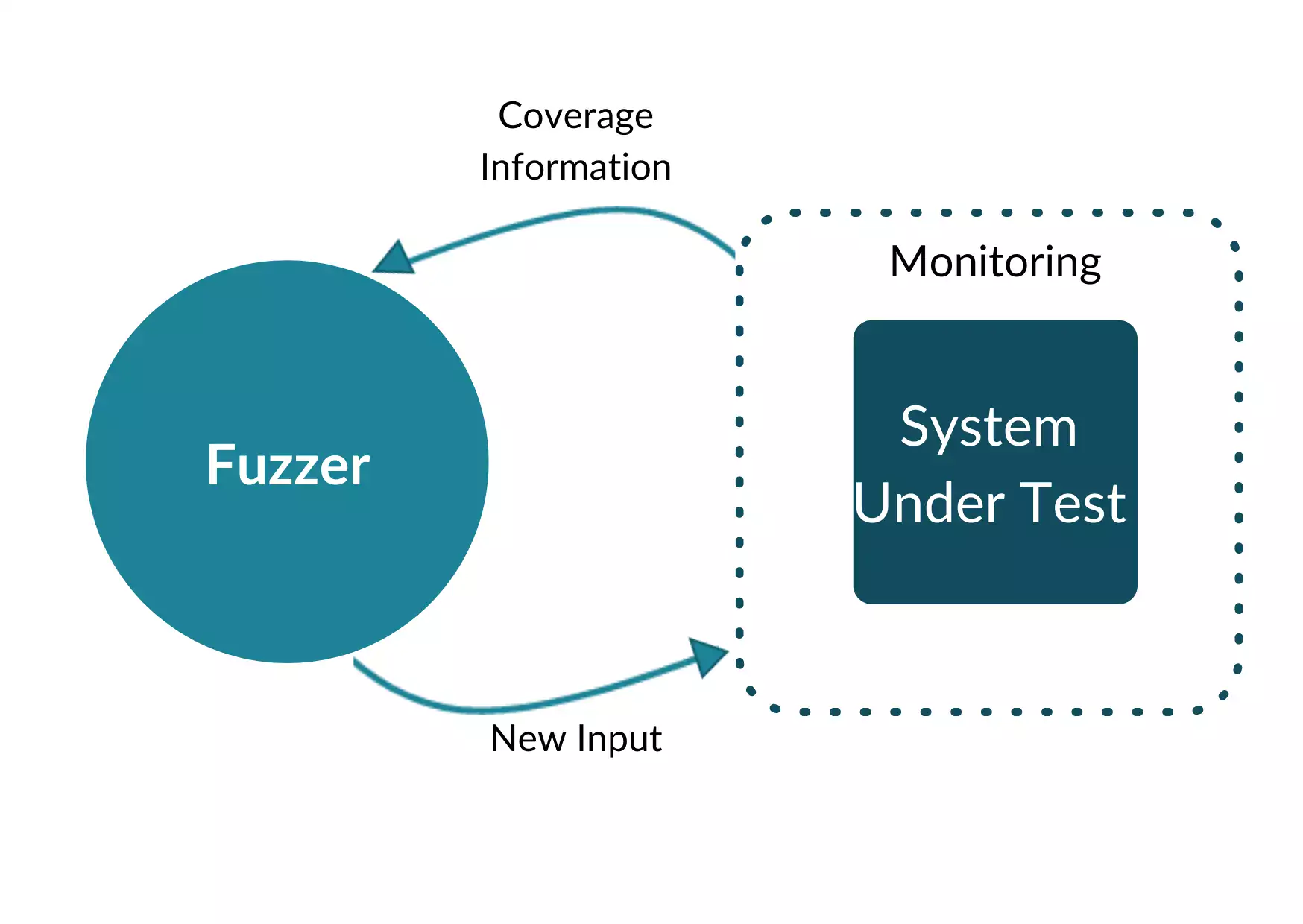
Paradigms
As fuzzers have evolved, there's a few paradigms that have emerged as being highly effective: coverage-guidance, mutations, and compiler instrumentation
Mutations

In the beginning fuzzers where quite primitive with how they generated inputs, usually just random bytes. This is very inefficient, as usually just relying on luck to find your way to an input that will not be immediately rejected by the PUT is not a fruitful approach. Modern fuzzers employ a mutation-based fuzzing technique, as mentioned before, where they take an initial corpus of seeds. These seeds are expected to be semantically correct and valid inputs that the program will not error out on. Mutating aims to discover interesting inputs from a pool of valid and semantically correct corpus of seeds, yielding a much higher success rate. Mutation algorithms vary widely, some use stochastic modeling to try to do mutations on specific parts of the input that have historically shown success. Mutation algorithms are either deterministic or non-deterministic, but most will include some kind of randomness. In the case of deterministic mutation algorithms, it’s common to seed a random number generator. Most popular fuzzers tend to do simple byte/bit-level mutations on the input, such as swapping bytes, deleting bytes, adding bytes. This typically provides a slow enough change in the seed population such that it’ll escape local minimums, while not missing interesting inputs.
Coverage
For a fuzzer to be Coverage-Guided, the fuzzer keeps track of how much and what sections of the PUT it’s inputs have covered throughout the fuzzing campaign. Coverage can be collected in multiple different ways. Some common ways are:
- block coverage: Usually this is in the form of basic blocks as determined by scope of the resulting program. A basic block contains all instructions which have the property that if one of them is executed, then all the others in the same basic block are.
- edge coverage: Edge coverage uses the edges between blocks to generate a more intuitive understanding of execution flow. Consider the following graph:
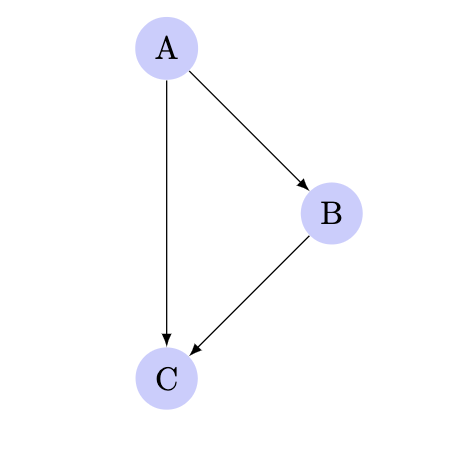
If blocks A, B, and C are all covered, we know for certain that the edges A→B and B→C were executed, but we still don’t know if the edge A→C was executed. Such edges of the control flow graph are called critical. The edge-level coverage simply splits all critical edges by introducing new dummy blocks and then instruments those blocks. This allows us to have better understanding on coverage between edges and reduce the number of critical edges we have in the program. By simply taking them out, it disambiguates coverage:
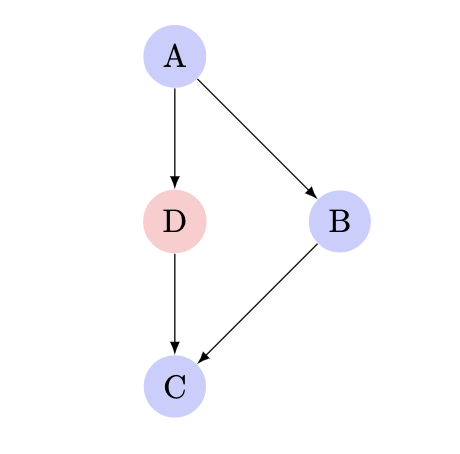
- line coverage: requires access to the original source code and looks at coverage on a per-line basis.
Typically, programs don’t have this block data readily available. Most fuzzers, including AFL/AFL++ use compiler instrumentation to acquire this data. External function calls are injected at certain points in the compilation step to send data to the fuzzer every time one of these edges or blocks is hit. For the case of AFL++, LLVM CLANG compiler was patched to inject coverage tracking as part of the compilation step. Then, a coverage bitmap is commonly used to keep track of coverage events, this is then updated upon the completion of each seed finishing it’s run.
Visibility & Instrumentation
Visibility refers to the amount of information that is exposed to the runtime of the fuzzer, on the PUT.
- Blackbox: The fuzzer has no access to the source code and does not rely on visibility in the form of symbols or sections in the target binary.
- Graybox: The fuzzer has some visibility on the original source code, but through the form of symbols and special compiler instrumentation that was done in the beginning of the fuzzing campaign.
- Whitebox: The fuzzer has full visibility into the source code of the program, giving them full information on logic and structure.
Most fuzzers have found that Graybox fuzzing is the most efficient, if we're able to combine static analysis techniques from the compiler before runnning a fuzzing campaign then we should be able to significantly trim down our input seeds and get the most out of our corpus. Blackbox fuzzing is really difficult because we're just looking at a binary blob and trying to figure out what's happening at every step - while not impossible - very hard to decipher. While on the other end Whitebox fuzzing has full access to source code during the fuzzing campaign so it can be really useful for running dynamic analysis as we're fuzzing and triaging bugs in real time, but it has it's tradeoffs as usually these techniques can be difficult to apply universally to all kinds of code. Graybox seems to be a good compromise of allowing enough observability for instrumentation and pre-campaing static analysis while not tying us down to a particular programing language or structure.
Modern Fuzzers
Let's look at a general modern architecture of a mutation based fuzzer. This is taken from the AFL++ docs directly, it encapsulates well what most fuzzers do and the execution flow from a top-level perspective.
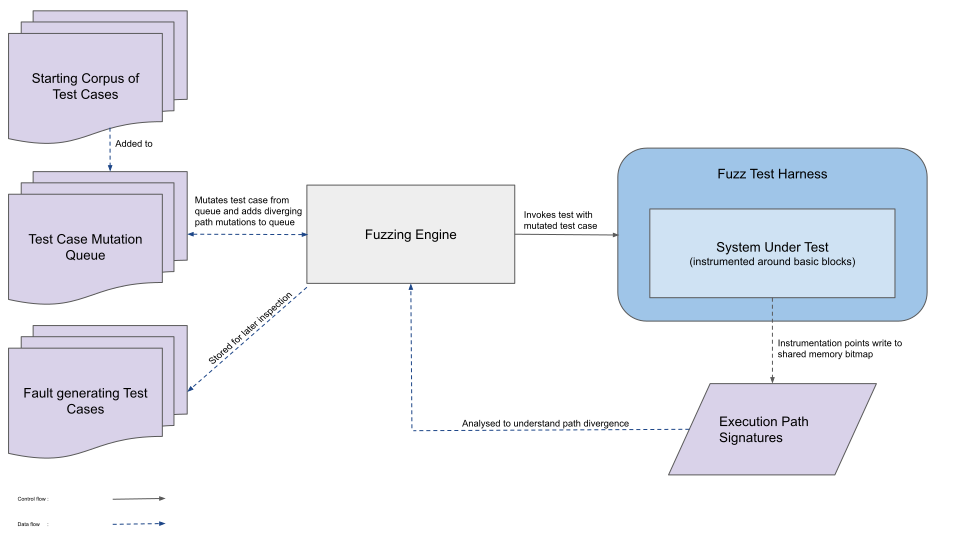
In this image, the PUT is being wrapped by a harness. A harness is a program that is used as the entry point to the PUT, usually this is the case when the PUT is a library and so there’s no main entry point to exec test inputs. Harnesses are a really common way of fuzzing targets, and can also be used to do arbitrary setup on the target before running the input. This is sometimes required as a target library might require a lot of interaction and setup before getting to the desired part of the program to fuzz. A popular fuzzing engine called LibFuzzer is built as a modular library just for this purpose, instead of being a standalone executable like AFL/AFL++. LibFuzzer focuses on doing in-process fuzzing as opposed to the standard out-of-process fuzzing that AFL/AFL++ does. This gives users a flexibility with building niche targeted harnesses and fuzzing campaigns, that might otherwise be difficult with out-of-process fuzzers.
AFL++ is by far the most popular fuzzer, it’s a Coverage-Guided Mutation-based Graybox Fuzzer. It's the spiritual and predominate successor of the original AFL project, which is now the industry standard and has become ubiquitous within the Security and Fuzzing field. It’s written in C++ and is open source, giving it a great advantage in receiving open source contributions. It’s being openly developed on Github, with over 6,000 commits and over 150 contributors. AFL++ is one of the most contributed open source projects and an essential security tool in the open source community. The design of AFL++ also employs a subset of genetic algorithms for doing mutations. Mutated test cases that produce new state transitions within the program are added to the input queue and used as a starting point for future rounds of fuzzing. They supplement, but do not automatically replace, existing finds. The current number of seeds that are ready to be fuzzed can be considered the population. The objective is to move that population, individual by individual, towards higher coverage. AFL++ heavily relies on compiler instrumentation and pruning of the initial corpus, through different adjacent programs that attempt to optimize initial seed count and coverage of each seed. By pre-executing and running some heuristics on a corpus, these tools can trim down the corpus into smaller and more significant inputs.
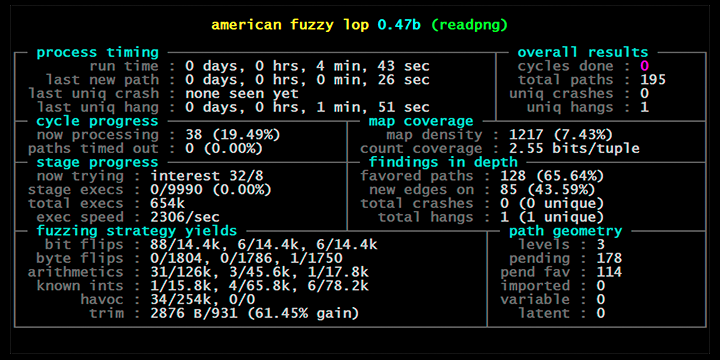
However there is new approaches emerging in the space that attempt to make small incremental changes to AFL++ and improve its performance on several metrics. Notably AFLGo is an extension of AFL that makes it a directed fuzzer, which means that it will target certain locations in the PUT to get to and it will do whatever it can to lead execution towards that direction.
There are other interesting projects that are building something completely different from AFL/AFL++. LibAFL is an advanced fuzzing library created in Rust that allows you to slot together a custom fuzzer, through a series of standalone components. It's extremely versatile and composable nature has made it a great player in scalable fuzzing techniques. Or the work being done by Google on Centipede (recently merged into FuzzTest), a new distributed fuzzer that aims to alleviate some of the scaling limitations that LibFuzzer and other fuzzers have had when running in distributed environments with large seed sizes and long runnning programs. There are also many different non coverage-guided paradigms in the fuzzing community that are leveraging the core fuzzing functionalities to find bugs, such as differential fuzzing and targeted fuzzing techniques.
Shameless plug:
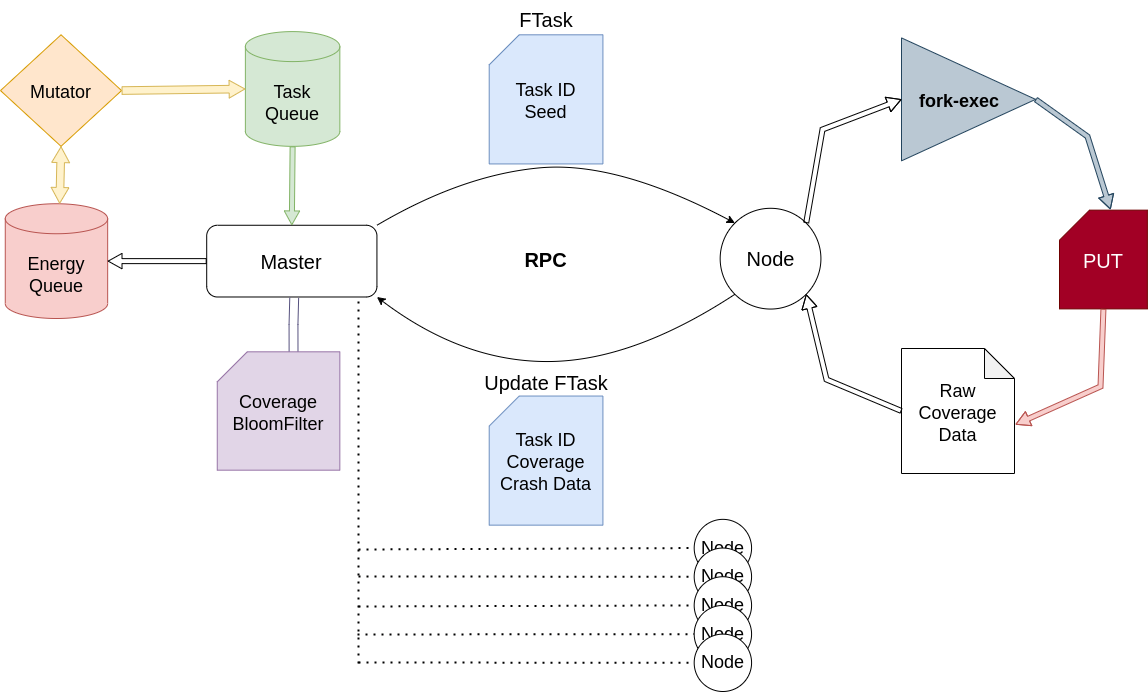
I wrote my Thesis on a similar distributed fuzzer that I've been building called Hopper, a new distributed fuzzer that takes a lot of the modern distributed computing techniques that exist in distributed systems and caching to optimize the performance of fuzzers in a distributed environment. Hopper is a standalone project but it was designed as a modular library, one of the biggest hopes for Hopper is to facilitate the use of Fuzzers while developing a scalable platform for distributed fuzzing. Many fuzzers can be difficult to configure and run correctly. Usability is an often overlooked issue with new software proposals in fuzzing. Hopper prides itself on being easy to use, while still providing the core utilities of a fuzzer and the parallelism of a distributed system. Hopper provides a set of tools to containerize, distribute, and arbitrarily spawn fuzzing agents. Apart from the modular design of the core Master and Node Go software, we also provide scripts to facilitate campaigns. We consider this part of the contribution that Hopper is making to fuzzing, and shifting towards infrastructure-aware software proof of concepts. Just because it’s a proof of concept, doesn’t mean it should be impossible to use. An easy to use fully dockerized demo is available on the Hopper GitHub. Hopper's top level architecture:
If you want to learn more about fuzzing, I'd recommend you read The Fuzzing Book and just get involved in the Fuzzing community